

Простой способ обойти блокировки – купи VPN через Телеграмм-бот:
|
ИИ учится сам у себя – решит ли это проблему нехватки данных?

Системы искусственного интеллекта могут вскоре столкнуться с нехваткой текстовых данных для обучения. Доклад Epoch AI от 2022 года спрогнозировал, что минимум к 2026-2030 годам компании исчерпают общедоступные данные.
Прогнозы Epoch AI указывают на исчерпание низкокачественных языковых данных к 2030-2050 годам, высококачественных языковых данных до 2026 года и визуальных данных к 2030-2060 годам. Такие данные жизненно важны для обучения моделей машинного обучения, и их дефицит может замедлить прогресс в ИИ.
Высококачественные данные играют ключевую роль в обучении продвинутых моделей ИИ, таких как GPT-3, требующих точных и надежных данных для высокой производительности.
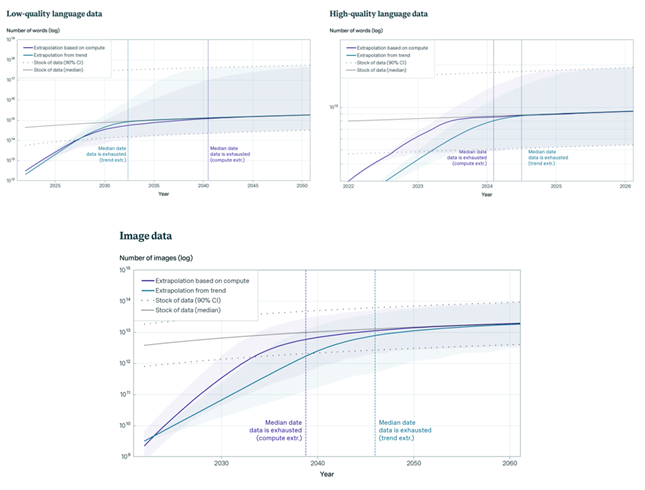
Графики исчерпания языковых и визуальных данных
Epoch AI сравнивает такую тенденцию с «золотой лихорадкой», истощающей ресурсы. В ближайшем будущем такие компании, как OpenAI и Google, будут соревноваться за качественные данные, иногда платя за них. Например, фирмы заключают сделки с Reddit и новостными сайтами.
Со временем новых блогов, статей и комментариев в соцсетях будет недостаточно, что вынудит компании обращаться к личным электронным письмам пользователей или полагаться на менее надежные синтетические данные, создаваемые самими чат-ботами. Если данные будут исчерпаны, компании не смогут эффективно масштабировать свои модели, что затруднит улучшение их работы.
В России и ищешь VPN? Покупай через Телеграмм-бот:
|
Epoch AI впервые сделали свои прогнозы 2 года назад, предсказывая нехватку данных к 2026 году. С тех пор появились новые техники, позволяющие лучше использовать уже имеющиеся данные. Однако пределы все равно существуют, и теперь исследователи предсказывают, что общедоступные данные иссякнут в ближайшие 2-8 лет.
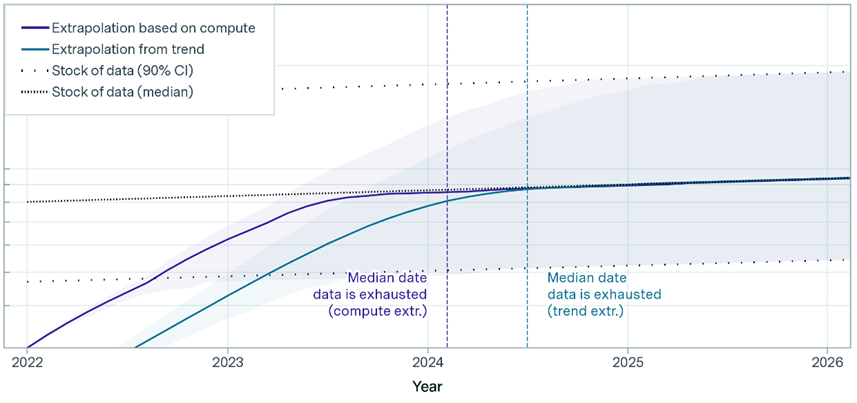
Исчерпание количество данных к 2026 году
Согласно новому исследованию Epoch AI, объем текстовых данных для языковых моделей ИИ увеличивается примерно в 2,5 раза в год, а вычислительные мощности — в 4 раза. Компания Meta* заявила, что их предстоящая модель Llama 3 обучена на 15 триллионах токенов.
Ученые их Университета Торонто считают, что создание более квалифицированных ИИ может происходить за счет обучения моделей, специализированных для конкретных задач. Также отмечается, что обучение ИИ на данных, которые они сами производят, может ухудшить их производительность.
Если человеческие тексты останутся критически важными для ИИ, Reddit и Википедия будут вынуждены пересмотреть, как их данные используются. В Wikimedia Foundation надеются, что люди продолжат вносить свой вклад, несмотря на рост автоматически сгенерированного контента.
Исследование Epoch AI говорит, что оплата людям за создание текста для ИИ не будет экономически выгодной. Поскольку OpenAI работает над обучением следующего поколения своих GPT-моделей, компания уже экспериментирует с генерацией синтетических данных, но глава OpenAI Сэм Альтман выражает сомнения в их эффективности и опасение за зависимость от таких данных.
* Компания Meta и её продукты признаны экстремистскими, их деятельность запрещена на территории РФ.
Невидимка в сети: научим вас исчезать из поля зрения хакеров.
Подпишитесь!
Надежный VPN сервис — это виртуальная частная сеть, которая обеспечивает высокую степень защиты и конфиденциальности при использовании интернета. Термин "надежный" относится к нескольким ключевым аспектам, которые делают VPN сервис безопасным и эффективным для пользователей.
Надежный VPN защищает ваши личные данные от слежки со стороны хакеров, интернет-провайдеров и государственных органов.
Использование надежного VPN помогает скрыть ваш IP-адрес и обеспечивает анонимность при серфинге в интернете.
Надежный VPN сервис — это важный инструмент для обеспечения безопасности, конфиденциальности и анонимности в интернете. Выбор надежного VPN поможет вам защитить свои данные, обойти блокировки и улучшить свой опыт онлайн-серфинга.




Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.